

A new open-source AI research startup, Deep Cogito, has come out of stealth mode with a bold mission: to rethink how intelligence can be scaled. Founded in San Francisco in June 2024 by former DeepMind and Google researchers Dhruv Malhotra and Drishan Arora, and backed by early investment from South Park Commons, the company has now unveiled its first major release—Cogito v1, a suite of advanced language models ranging from 3B to 70B parameters.
Unlike many reasoning-focused models that suffer from high computational demands and latency, Cogito models are engineered to seamlessly shift between a standard mode for speed and a reasoning mode for complex tasks. This flexibility allows them to maintain high performance while remaining efficient—solving a long-standing tradeoff in AI deployment.
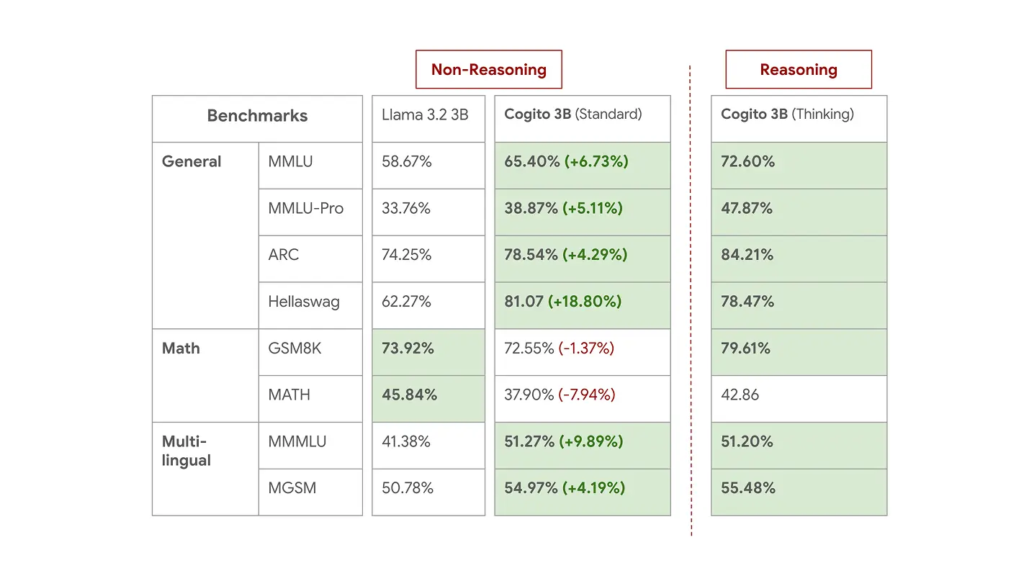
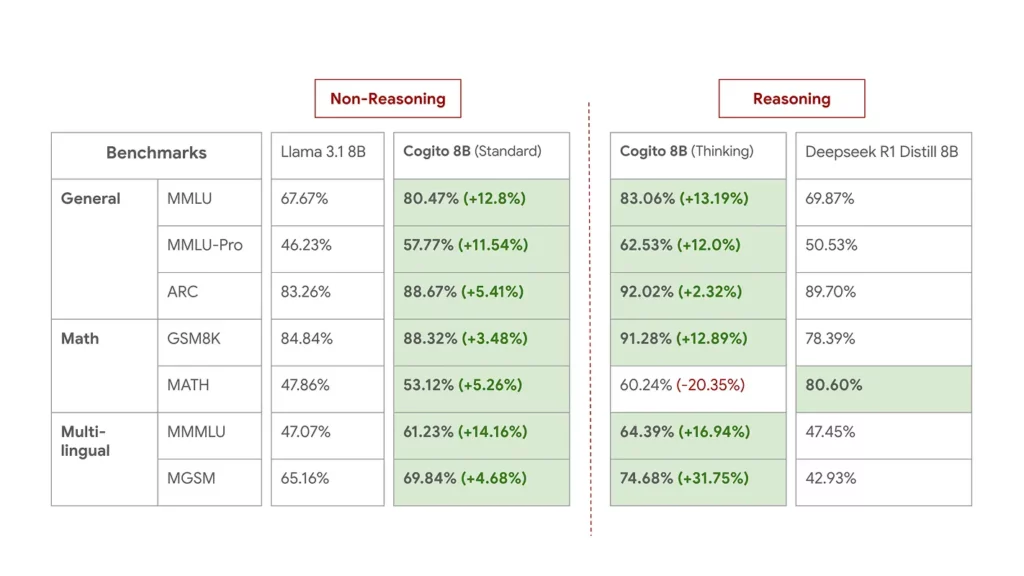
Despite the compact development timeline, the results are impressive. According to the company, its flagship 70B model not only matches but outperforms Meta’s LLaMA 4 109B Mixture-of-Experts (MoE) model across key benchmarks. These include mathematical reasoning, language comprehension, and LiveBench, a well-regarded general-purpose AI evaluation.
The driving force behind this breakthrough is a novel training methodology called Iterated Distillation and Amplification (IDA). Rather than relying on traditional strategies like reinforcement learning from human feedback (RLHF) or distilling from larger teacher models, IDA enables the model to improve through cycles of self-improvement. In each iteration, the model first engages in more compute-intensive reasoning—often using recursive thinking or internal subroutines—to generate higher-quality responses. These enhanced outputs are then distilled into the model’s own parameters, making them part of its native capabilities. Over time, this iterative loop allows the model to improve its performance based on its own reasoning rather than being capped by the limitations of a fixed human overseer or a larger model.
This approach is not only more scalable but also significantly more time-efficient. Deep Cogito developed its 70B model in just 75 days, yet it has demonstrated performance superior to models trained for much longer using vastly greater compute resources.
Built on open-source foundations like Meta’s LLaMA and Alibaba’s Qwen, Cogito models integrate proprietary alignment strategies that push the limits of what’s possible in current-generation language models. Internal evaluations show the Cogito 70B model outperforming top-tier alternatives such as DeepSeek’s R1 and Meta’s LLaMA 4 Scout across a range of reasoning and language tasks.
Looking ahead, Deep Cogito plans to release even larger Mixture-of-Experts (MoE) models with parameter sizes reaching 109B, 400B, and 671B. Updated checkpoints for the current model family are also on the way—all under open license, maintaining the team’s commitment to open science and reproducibility.
With Cogito v1, Deep Cogito isn’t just chasing benchmark dominance. It’s laying the groundwork for a new era of scalable, self-improving AI—one that could bring us a step closer to general superintelligence.





















