
In the ever-evolving landscape of technology, enterprises find themselves navigating a dynamic and fiercely competitive environment. Amidst this backdrop, a sense of urgency has taken hold, fueled by the fear of falling behind and missing out on the immense opportunities brought forth by the latest advancements in large language models.
Enterprises across industries are increasingly recognizing the transformative power of Large Language Models (LLMs). Enterprises understand that failing to adapt and adopt these transformative tools could result in a significant disadvantage, stifling growth and innovation. They are now venturing into uncharted territories, embarking on a race to build their own LLMs.
Amidst these changes, an alternative solution that emerges is the arrival of open-source LLMs in the market. These pre-built models, developed by a community of experts, offer a compelling option for businesses looking to leverage the power of AI without embarking on the complex and resource-intensive task of starting from scratch.
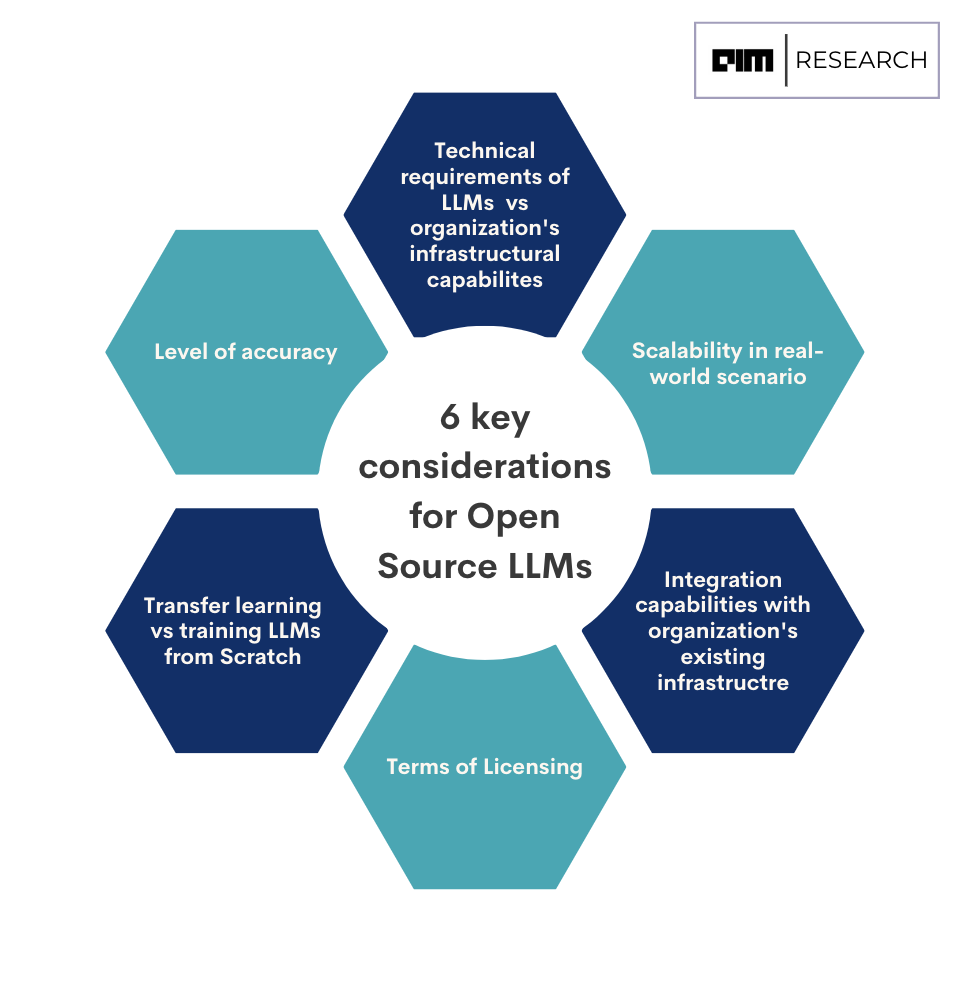
AIM Research has identified the following seven factors that enterprises need to consider in order to decide which open-source LLM to adopt.
Organizations should assess their hardware and infrastructure capabilities when adopting open-source large language models due to their significant computational demands. It is advisable to evaluate and upgrade existing resources, plans for scalability, and consider cloud-based solutions to ensure the efficient utilization of these models. Based on enterprises’ existing capabilities and resources, they can consider the most suitable open-source LLM.
It is crucial to evaluate the ability of a model to handle increasing demands as data sizes and computational requirements grow. It is recommended that such models should be adopted that have demonstrated scalability in real-world scenarios or have been specifically designed with scalability in mind.
Before selecting a specific open-source large language model, it is advisable to assess its integration capabilities. Enterprises need to consider factors such as the model’s compatibility with programming languages, frameworks, and APIs commonly used in the enterprise ecosystem.
Moreover, whether the model can be easily integrated into existing software applications or if any modifications or adaptations are required is also necessary to be scrutinized. Only such open-source LLM should be selected that seamlessly fits into an organization’s infrastructure and streamlines implementation thereby maximizing the benefits of the model’s capabilities.
When enterprises contemplate the adoption of an open-source LLM, it is essential to review and evaluate the licensing terms associated with the model. License type, permitted usage, modifications and distribution requirements, attribution obligations, compatibility with other licenses, and legal compliance need to be understood properly.
For instance, h2oGPT has Apache 2.0 license implying licensees are allowed to modify it and the modified version can be released for commercial purposes. Moreover, any derivative work need not be distributed under the same license. On the other hand, Open Flamingo based on DeepMind’s Flamingo model has an MIT license implying any modifications done on top of it can be distributed freely or even sold. However, the modified version needs to be accompanied by an MIT license.
Such a thorough review will ensure organizations can ensure that the chosen open-source LLM aligns with the organizations’ requirements, respects intellectual property rights, and complies with applicable laws and regulations.
Transfer learning in natural language processing (NLP) involves utilizing the acquired knowledge of a pre-trained model to enhance the performance of a new task. This is accomplished by fine-tuning the pre-trained model on the new task, and adding new layers while keeping the pre-existing weights unchanged.
While training a language model from scratch involves training the model from the ground up on a specific task or domain using a large labeled dataset. This approach requires substantial computational resources and labeled data to achieve good performance.
It is important for enterprises to consider whether the open-source LLM can be trained through transfer learning or needs to be trained from scratch before deciding which open-source LLM to go for.
Given the computational resource requirement, at a glance training from scratch seems impractical. However, transfer learning may not always fetch optimal outcomes. A lot depends on the extent to which the pre-trained data aligns with the data for the new task to be accomplished, among other factors.
With numerous open-source LLMs available in the market, it becomes pertinent for companies to assess how accurate their level of output is for them to choose the most suitable open-source LLM. The higher the accuracy level, the better is for the enterprise to adopt the LLM.
Now accuracy can refer to different aspects and high accuracy in one aspect doesn’t necessarily mean high accuracy rate in other aspects as well. For instance, Lazarus is an open-source LLM whose level of accuracy is high in terms of common sense inference but pretty average when it comes to multitasking accuracy. Or for that matter, Llama fares high in terms of common sense inference but average if assessed on the level of truthfulness in generating answers to questions.
Enterprises need to zero down on that open-source LLM whose level of accuracy is high on parameters that closely align with organizational requirements.
Based on a thorough assessment of these aspects, organizations can select an open-source LLM that aligns with their infrastructure, legal requirements, computational resources, and specific needs, enabling them to leverage the transformative power of language models effectively.




